|
Tutorial
2: Extraction and Conversion of Protein ID
 In
the second tutorial, we will be extracting the protein id names from
the data set. In this step, the New Line Selection and 'Quoted Data' rules will be used. In Vect, make sure you are in the 'Input Data' panel with the AC006439.txt file opened. As shown in the document,
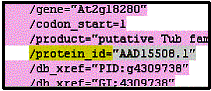
the protein id appears only under the CDS block. In
the second tutorial, we will be extracting the protein id names from
the data set. In this step, the New Line Selection and 'Quoted Data' rules will be used. In Vect, make sure you are in the 'Input Data' panel with the AC006439.txt file opened. As shown in the document,
the protein id appears only under the CDS block.
Right click and drag
over 'protein_id=' and select New Line Condition from the pull down
menu. A yellow block will appear. Select the protein id so that a
grey highlighted region appears. (do this by left-clicking once on the id such as AAD15508) As in the previous gene sequence step,
select the 'Move' button from the icon panel.
In the 'Convert Data' panel select 'Insert' and select the 'Quoted Data' rule. Give your
rule a descriptive name and specify which data set you would like to
use.(the one you just imported over, ie. the protein ids). Fill the 'nothing' blocks with quotes(") as shown in the following
diagram. To be certain you have the right data set expand the yellow
arrow. You should have 25 lines of protein id names.

Select Rule 2 (the concatenated sequence) then Select
the 'Copy' button from the icon panel to move your data to the 'Output
Data' panel. Format the data set and view the changes
by selecting the 'Output' icon in the icon panel.
The tag should not
be modified but can be moved around. If users wish to
limit the output to a set number of lines, the tag may be edited
by including a ':width' before the closing bracket (>). This restricts
the body from flowing past the specified width. Example: <gene
sequence:60>.
To
show the Perl code, move to the 'Perl Program' panel and select 'Compile.'
Your Perl program appears as shown below. To run the program generated,
select the 'Run' icon. A new window will appear with the results of
your Perl program.


|

